
深度学习在序列化推荐中的应用(3)
前言
这篇是继 深度学习在序列化推荐中的应用 和 深度学习在序列化推荐中的应用(2) 的补充理解
DIN
base idea:设计了一个local activation unit来学习用户行为历史的兴趣点
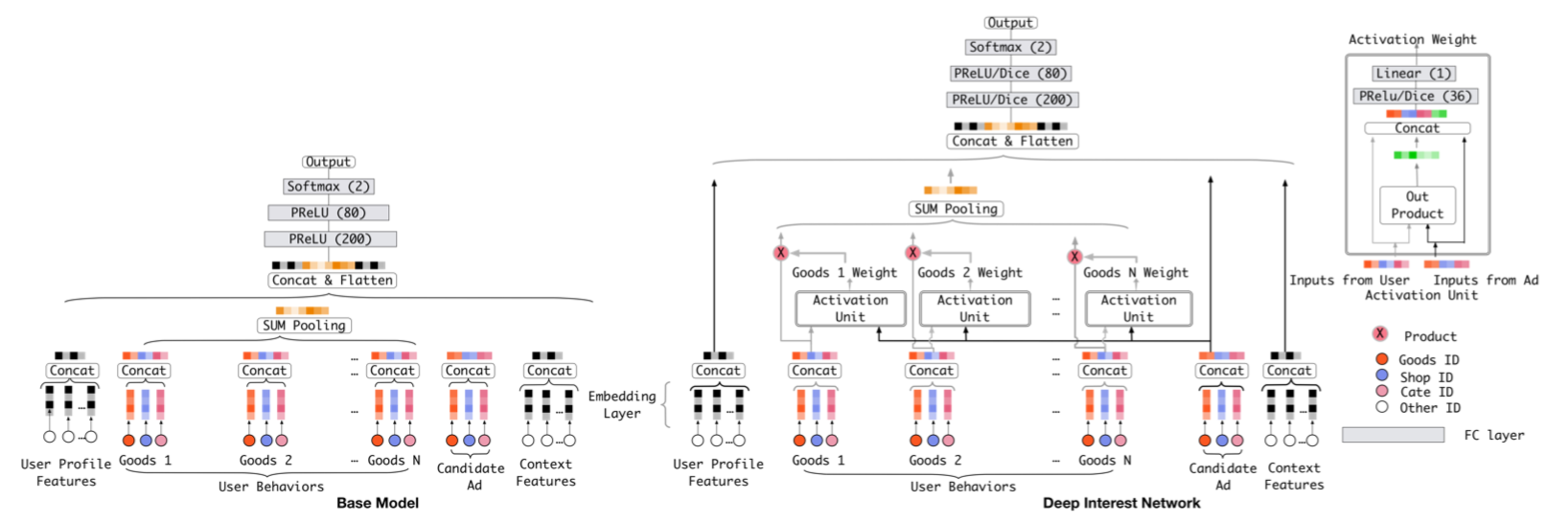
一般传统的深度模型是将各类的用户信息(包括用户行为)查询到Embeddings之后通过各种MLP层来灌入到最后隐层,而上图(右)的DIN模型中 根据当前Item的信息与 用户的行为历史进行交互获取其历史中的兴趣,其核心就是local activation unit:
- 一般item和行为历史的信息都会包括多个维度信息,比如paper中包含
id,cateid,shopid等,item和单个历史行为信息的Embeddings用$E^q$和$E^f_i$来表示 - 构建他们两综合输入信息,一般是拼接、外积、差集等,$v_i = [E^q,E^f_i,E^q-E^f_i,E^q \odot E^f_i]$
- 然后经过若干层
MLP层,记得最后一层不带激活函数并且输出单元为1,该值就是item与当前历史行为的权重$w_i$ - 则最终用户的兴趣向量为带权重的求和$v_u =\sum_i w_i v_i$
- 拿到该向量之后,其余操作与普通的传统模型一致了
其实细致一点可以发现,local activation unit与attention其实很像,最大的差别就是attention在聚合前会使用Softmax进行归一化,而Din不会,作者的解释是不用 归一化是为了更加凸显用户兴趣,他可以得到一个更大的向量值
同时在DIN里面还提到了在训练时使用Mini-batch Aware正则项可以较为明显的提升效果,针对L2正则项,在Mini-batch中的公式是$$L_2(W) = \sum_j^K \sum_{m=1}^B \frac{\alpha_{mj}}{n_j} \parallel w_j \parallel ^2 $$
其中$\alpha_{mj}$表示在当前batch $m$中含有特征$j$,则为1,否则为0 另外$n_j$为特征$j$在总样本中出现的次数
这种方式在Mini-batch下使用是几乎等价于Full-batch,其物理意义是特征频次高的的不怎么需要正则化,而低频的需要正则化
DIEN
实际上用户的行为序列一般是一个长期行为,而他在整个序列中他的兴趣点是在变化的,所以DIEN的作者就是希望能提取用户的兴趣变化行为来提升模型。
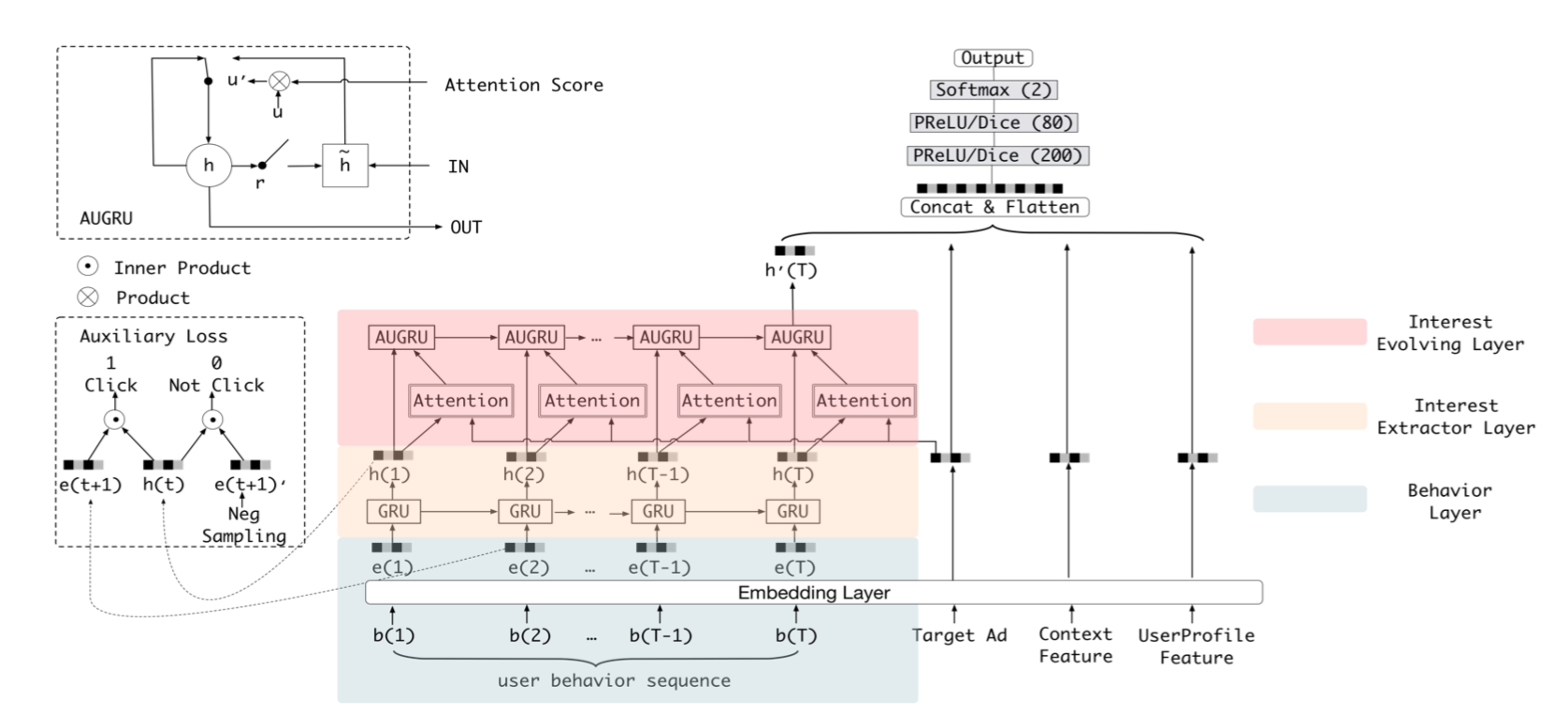
DIEN模型主要的差别是他有一个抓住用户兴趣衍化的模块,其余与传统的排序模型差不多,关于兴趣提取模块:
Behavior:根据行为itemid作为序列输入,查表之后得到向量$e_t$Interest Extractor Layer:这层需要是为了提取用户的兴趣,使用经典的GRU进行建模,但是作者同时引入了一个辅助loss:根据上一个step的输出$h_t$来预测当前的item是否会点击(类似GRU4REC):$$L_{aux} = -\frac{1}{N} \sum_{i=1}^N \sum_t \text{log} \sigma(h_t,e_{t+1}) + log(1-\sigma(h_t,e_{t+1}))$$Ienerest Evolving Layer:这里用Attention来更新GRU中gate的方式来捕获用户兴趣的变化$$\alpha_t = \frac{exp(h_t We_a)}{\sum_{j=1}^T exp(h_j W e_a)} \\ \tilde{u_t} = \alpha_t \cdot u_t \\ h_t = (1-\tilde{u_t}) \cdot h_{t-1} + \tilde{u_t} \cdot \tilde{h_t}$$- 最终
DIEN模型的loss为:$$L = L_{target} + \alpha L_{aux}$$
DIEN相对DIN是考虑了序列中的时序问题,在建模时用Attention来捕获用户兴趣的变化
DSIN
按照DIEN,用户的行为序列中的兴趣其实会变化的,而DSIN观察发现一整个序列往往可以被分为多个不同的Session,同一个Session中的用户兴趣很相似,而不同Session之间的用户兴趣其实差异很大,因此DSIN提取了一个基于Session的用户兴趣神经网络: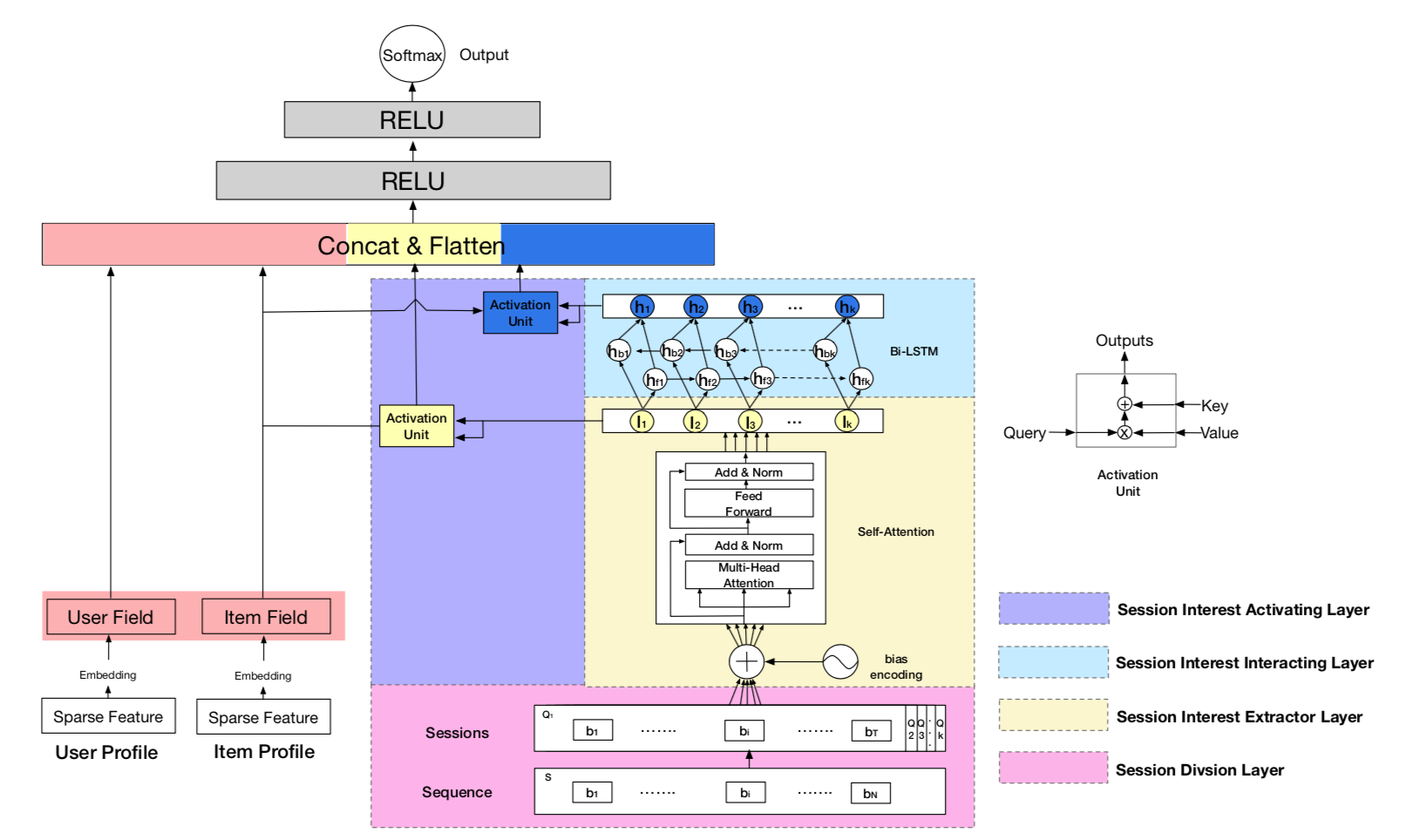
这边的用户兴趣主要分为4个层:
Session Divsion Layer:将用户序列$S$分为$k$个Session $Q$,这边$Q_k = [b_1,..,b_i,…,b_T]$,$T$则为单个Session的长度Session Interest Extractor Layer:针对每个Session始终Multi-head Attention来提取Session特征,同时还设计了一种新的Position Encoding:$$BE(k,t,c) = w_k^K + w_t^T + w_c^C$$,则输入到Multi-head Attention的为$Q = Q+BE$,过完Attention之后再过正常的FFN层,最终单个Session用average来表示 $$I_k = Avg(I_k^Q)$$Session Interest Interacting Layer:这些Session将会重新构建成一个新的序列,这个序列接下来输入到BiLstm,这里单个Session的前向/后向 向量进行外积之后得到 交互后的向量 $$H_k = h_{fk} \odot h_{bk}$$Session Interest Activating Layer:在用户兴趣激活层,针对$I_k$和$H_k$分别在过一层Attention,这里这里过Attention的时候会加上目标id的信息,然后得到$U^I$和$U^H$,Attention的样例式子为:$$\alpha_k^I = \frac{exp(I_k W ^I X^I)}{\sum_k^K exp(I_k W ^I X^I)} \\ U^I = \sum_k^K \alpha_k^I I_k$$- 最终将$U^I$和$U^H$以及用户和Item的embedding信息拼接之后输入到NN模型
该模型给我的最大感受就是:哇,这计算量真大!!!
seqFM
传统的FM模型可以很好的处理模型中的稀疏特征,但是实际中的动态序列特征对于FM模型而言无法处理,因此SeqFM就使用带mask的Self-Attention结合FM来处理实际的稀疏和动态输入的模型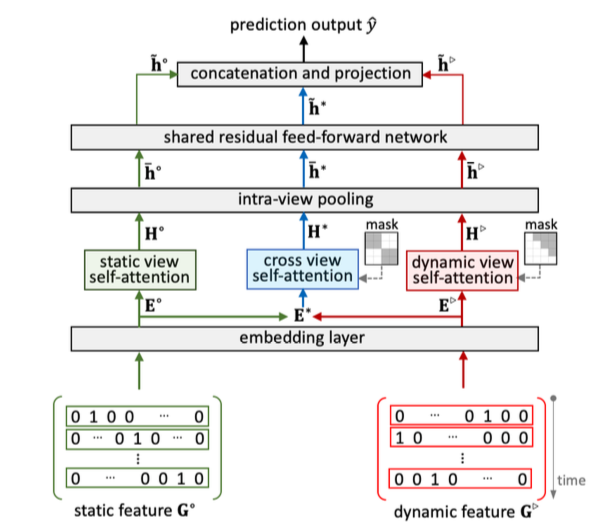
模型的特征分为静态特征$G^{\circ}$ 和动态序列特征 $G^{\triangleright }$,他们对应的Embedding分别称为$E^{\circ}$ 和 $E^{\triangleright }$接下来会用三种Self-Attention来提取三个不同视角的特征:
静态视角特征:直接将稀疏离散特征过Self-Attention:$$G^{\circ} = \text{softmax} (\frac{E^{\circ}W_Q^{\circ} \cdot (E^{\circ}W_K^{\circ})}{\sqrt{d}})E^{\circ}W_V^{\circ}$$动态视角特征:由于动态特征是带有先后序列关系,所以这里发生交互是有方向性的,paper中用Mask Self-Attention来提取特征:$$G^{\triangleright} = \text{softmax} (\frac{E^{\triangleright}W_Q^{\triangleright} \cdot (E^{\triangleright}W_K^{\triangleright})}{\sqrt{d}} + M^{\triangleright})E^{\triangleright}W_V^{\triangleright}$$ 这里的$M^{\triangleright}$是一个mask功能的常量矩阵
$$m_{i,j} = \left\{\begin{matrix} 0 & if i \geq j & \\ - \infty & otherwise& \\ \end{matrix}\right.$$交叉视角特征:同时将静态特征和动态特征放在一起进行Mask Self-Attention来提取交叉特征:$$G^{*} = \text{softmax} (\frac{E^{*}W_Q^{*} \cdot (E^{*}W_K^{*})}{\sqrt{d}} + M^{*})E^{*}W_V^{*}$$ 而 $E^{*} = [E^{\circ},E^{\triangleright }]$,这里这里在进行交互式 静态特征只能与动态特征交互,不能进行内部交互,所以mask矩阵为:$$m_{i,j} = \left\{\begin{matrix} 0 & if \quad i \leq n^{\circ} \leq j \quad or \quad j \leq n^{\circ} \leq i & \\ - \infty & otherwise& \\ \end{matrix}\right.$$
在得到三个视角的特征之后,经过Intra-View层进行特征压缩聚合(就是加权求和),然后再过残差以及映射层,输出最终的目标
这个实验结果必须贴一下,提升太多了: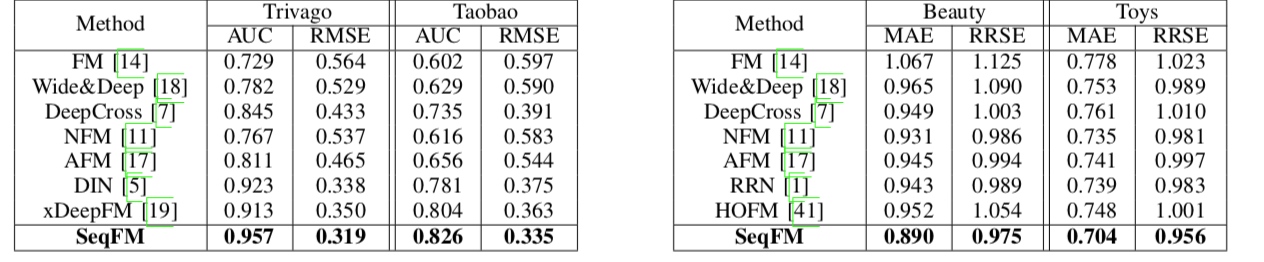
说一下我的理解:
- 整个结构非常灵活可控,静态特征那块可以换其他静态的离散特征提取器
- 其实
SeqFM并没有太多的序列考虑(除了masked那),没有和RNN系列的模型做对于,也没怎么和专门Self-Attention的作对比 - 同时静态特征那边的
Self-Attention我实际业务使用了,并没有太多特征 - 作者源码目前还没法下载到 不好做过多的判断,毕竟提升太多了
参考
- Zhou, Guorui, et al. “Deep interest network for click-through rate prediction.” Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018.
- Zhou, Guorui, et al. “Deep interest evolution network for click-through rate prediction.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. 2019.
- Feng, Yufei, et al. “Deep Session Interest Network for Click-Through Rate Prediction.” arXiv preprint arXiv:1905.06482 (2019).
- Chen, Tong, et al. “Sequence-Aware Factorization Machines for Temporal Predictive Analytics.” (2020).
